您现在的位置是:网站首页>内容内容
剖析阿里巴巴的云梯YARN集群技术使用_建站经验_网站运营_
![]() 2024-05-16 16:54:19
【512953070@qq.com】
419人已围观
2024-05-16 16:54:19
【512953070@qq.com】
419人已围观
简介 剖析阿里巴巴的云梯YARN集群技术使用_建站经验_网站运营_
阿里巴巴作为国内使用Hadoop最早的公司之一,已开启了Apache Hadoop 2.0时代。阿里巴巴的Hadoop集群,即云梯集群,分为存储与计算两个模块,计算模块既有MRv1,也有YARN集群,它们共享一个存储HDFS集 群。云梯YARN集群上既支持MapReduce,也支持Spark、MPI、RHive、RHadoop等计算模型。本文将详细介绍云梯YARN集群的 技术实现与发展状况。
MRv1与YARN集群共享HDFS存储的技术实现
以服务化为起点,云梯集群已将Hadoop分为存储(HDFS)服务与计算(MRv1和YARN)服务。两个计算集群共享着这个HDFS存储集群,这是怎么做到的呢?
在引入YARN之前,云梯的Hadoop是一个基于Apache Hadoop 0.19.1-dc版本,并增加许多新功能的版本。另外还兼容了Apache Hadoop 0.19、0.20、CDH3版本的客户端。为了保持对客户端友好,云梯服务端升级总会保持对原有客户端的兼容性。另外,为了访问数据的便捷性,阿里的存 储集群是一个单一的大集群,引入YARN不应迫使HDFS集群拆分,但YARN是基于社区0.23系列版本,它无法直接访问云梯HDFS集群。因此实现 YARN集群访问云梯的HDFS集群是引入YARN后第一个需要解决的技术问题。
Hadoop代码主要分为Common、HDFS、Mapred三个包。
Common部分包括公共类,如I/O、通信等类。
HDFS部分包括HDFS相关类,依赖Common包。
Mapred部分包括MapReduce相关代码,依赖Common包和HDFS包。
为了尽量减少对云梯HDFS的修改,开发人员主要做了以下工作。
使用云梯的HDFS客户端代码替换0.23中HDFS,形成新的HDFS包。
对0.23新的HDFS包做了少量的修改使其可以运行在0.23的Common包上。
对0.23新的HDFS包做了少量修改使0.23的Mapred包能运行在新的HDFS包。
对云梯的Common包的通信部分做了hack,使其兼容0.23的Common。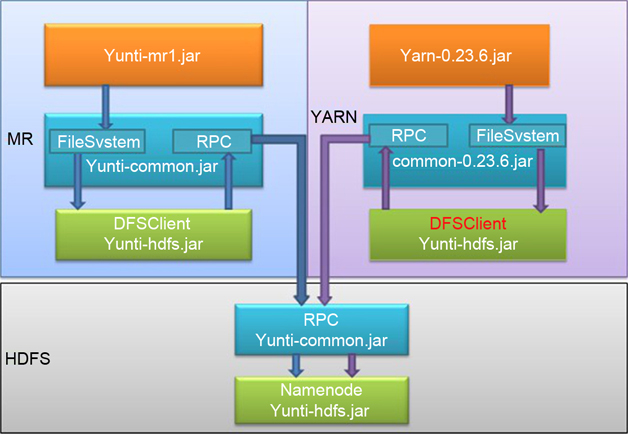
图1 云梯Hadoop代码架构
新的云梯代码结构如图1所示,相应阐述如下。
服务端
存储部分使用原有的HDFS。
MRv1计算集群中提供原MRv1服务。
YARN集群提供更丰富的应用服务。
客户端
云梯现有的客户端不做任何修改,继续使用原有的服务。
使用YARN的服务需要使用新客户端。
云梯MR服务切换为YARN要经过三个阶段
服务端只有MRv1, 客户端只有老版本客户端。
服务端MRv1和YARN共存(MRv1资源逐渐转移到YARN上), 客户端若需使用MRv1服务则保持客户端不变;若需使用YARN服务则需使用新版客户端。
服务端只剩下YARN,客户端只有新版本客户端。
通过上述修改,云梯开发人员以较小的修改实现了YARN对云梯HDFS的访问。
Spark on YARN的实现
云梯版YARN集群已实现对MRv2、Hive、Spark、MPI、RHive、RHadoop等应用的支持。云梯集群当前结构如图2所示。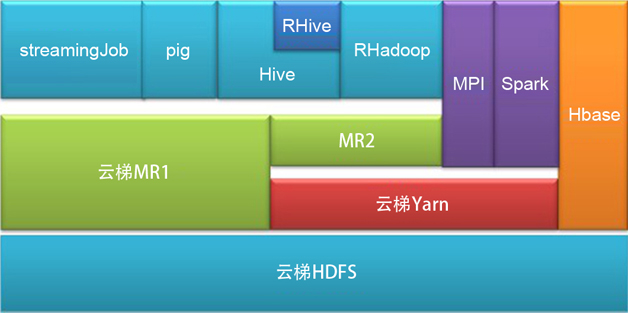
图2 云梯架构图
其中,Spark已成为YARN集群上除MapReduce应用外另一个重要的应用。
Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
Spark 的计算调度方式,从Mesos到Standalone,即自建Spark计算集群。虽然Standalone方式性能与稳定性都得到了提升,但自建集群毕 竟资源较少,并需要从云梯集群复制数据,不能满足数据挖掘与计算团队业务需求。而Spark on YARN能让Spark计算模型在云梯YARN集群上运行,直接读取云梯上的数据,并充分享受云梯YARN集群丰富的计算资源。
Spark on YARN功能理论上从Spark 0.6.0版本开始支持,但实际上还远未成熟,经过数据挖掘与计算团队长时间的压力测试,修复了一些相对关键的Bug,保证Spark on YARN的稳定性和正确性。
图3展示了Spark on YARN的作业执行机制。
图3 Spark on YARN框架
基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一 NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动 SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后 SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向 SparkAppMaster汇报并完成相应的任务。此外,SparkClient会通过AppMaster获取作业运行状态。
目前,数据挖掘与计算团队通过Spark on YARN已实现MLR、PageRank和JMeans算法,其中MLR已作为生产作业运行。
云梯YARN集群维护经验分享
云梯YARN的维护过程中遇到许多问题,这些问题在维护YARN集群中很有可能会遇到,这里分享两个较典型的问题与其解决方法。
问题1
问题描述:社区的CPU隔离与调度功能,需要在每个NodeManager所在的机器创建用户账户对应的Linux账户。但阿里云梯集群有5000多个账 户,是否需要在每个NodeManager机器创建这么多Linux账户;另外每次创建或删除一个Hadoop用户,也应该在每台NodeManager 机器上创建或删除相应的Linux账户,这将大大增加运维的负担。
问题分析:我们发现,CPU的隔离是不依赖于Linux账户的,意味着即 使同一个账户创建两个进程,也可通过Cgroup进行CPU隔离,但为什么社区要在每台NodeManager机器上创建账户呢?原来这是为了让每个 Container都以提交Application的账户执行,防止Container所属的Linux账户权限过大,保证安全。但云梯集群很早前就已分 账户,启动Container的Linux账户统一为一个普通账户,此账户权限较小,并且用户都为公司内部员工,安全性已能满足需求。
解决方案:通过修改container-executor.c文件,防止其修改Container的启动账户,并使用一个统一的普通Linux账户(无sudo权限)运行Container。这既能保证安全,又能减少运维的工作量。
问题2
问题描述:MRApplicationMaster初始化慢,某些作业的MRApplicationMaster启动耗时超过一分钟。
问 题分析:通过检查MRApplication-Master的日志,发现一分钟的初始化时间都消耗在解析Rack上。从代码上分 析,MRApplicationMaster启动时需要初始化TaskAttempt,这时需要解析split信息中的Host,生成对应的Rack信 息。云梯当前解析Host的方法是通过调用外部一个Python脚本解析,每次调用需要20ms左右,而由于云梯HDFS集群非常大,有4500多台机 器,假如输入数据分布在每个Datanode上,则解析Host需要花费4500×20ms=90s;如果一个作业的输入数据较大,且文件的备份数为3, 那么输入数据将很有可能分布在集群的大多Datanode上。
解决方案:开发人员通过在Node-Manager上增加一个配置文件,包含所有Datanode的Rack信息,MRApp-licationMaster启动后加载此文件,防止频繁调用外部脚本解析。这大大加快了MRApplicationMaster的初始化速度。
此外,云梯开发人员还解决了一些会使ResourceManager不工作的Bug,并贡献给Apache Hadoop社区。
在搭建与维护云梯YARN集群期间,云梯开发人员遇到并解决了许多问题,分析和解决这些问题首先需要熟悉代码,但代码量巨大,我们如何能快速熟悉它们呢?这 需要团队的配合,团队中每个人负责不同模块,阅读后轮流分享,这能加快代码熟悉速度。另外,Hadoop的优势在于可以利用社区的力量,当遇到一个问题 时,首先可以到社区寻找答案,因为很多问题在社区已得到了解决,充分利用社区,可以大大提高工作效率。
云梯YARN集群的优势与未来之路
当前云梯YARN集群已经试运行,并有MRv2、Hive、Spark、RHive和RHadoop等应用。云梯YARN集群的优势在于:
支持更丰富的计算模型;
共享云梯最大的存储集群,访问便捷、快速;
AppHistory信息存储在HDFS上,各种应用的作业历史都能方便查看;
相对于MRv1集群,云梯YARN能支持更大规模的集群;
相对于MRv1集群,云梯YARN集群支持内存和CPU调度,资源利用将更加合理。
未来,云梯将会把大多业务迁移到云梯YARN集群。针对YARN版本,云梯将增加资源隔离与调度,增加对Storm、Tez等计算模型的支持,并优化YARN的性能。